
안녕하세요, BALL 입니다!
오늘은 머신러닝 알고리즘 ‘회귀분석'에 대한 이야기를 가지고 왔습니다.
들어가기 전 !
'회귀'는 주로 머신러닝을 배우기 시작할 때,
가장 먼저 배우는 첫 부분에 위치하곤 하는데요.
회귀 모델 안에서도 다양한 개념들이 존재합니다.

그렇다면 '회귀분석' 이란 무엇일까요 ?
회귀 분석이란,
데이터 값이 평균과 같은 특정한 값으로 돌아가려는 경향을 이용한 통계학 기법입니다.
이때, 회귀는 통계적으로 여러 개의 독립변수(x)와 한 개의 종속변수(y) 간의
상관관계를 모델링하는 기법을 의미합니다.

즉, 회귀 분석은 데이터를 가장 잘 설명하는 최적의 회귀식을 찾는 과정입니다.
위 그림의 w0, w1, … 를 회귀계수 (coef)라고 하며,
회귀 분석을 통한 예측은 주어진 피처와 결정 값을 기반으로 학습하여
최적의 회귀계수를 찾아내는 것이 중요합니다.
*머신러닝에서 독립변수 = 피처, 종속변수 = 결정 값
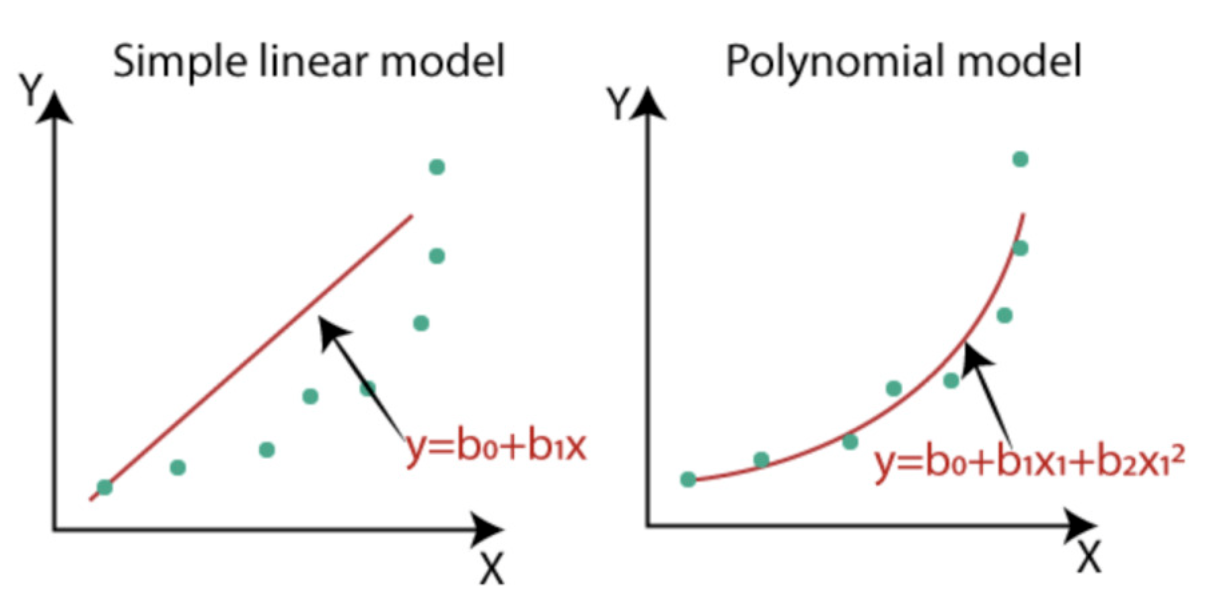
이때 회귀 계수의 유형과 독립변수의 개수에 따라
회귀 분석의 유형이 나뉩니다.
회귀 계수가 선형이라면 선형 회귀, 아니면 비선형 회귀입니다.
독립변수가 하나이면 단일 회귀, 여러 개면 다중 회귀로 나뉩니다.
오늘 포스팅에서는 가장 많이 사용되는
선형 회귀를 집중적으로 다뤄보도록 하겠습니다 !
선형 회귀는 실제 값과 예측값의 차이
즉, 잔차(오류값)를 최소화하는 직선형 회귀선을 최적화하는 방식입니다.
이때 오류값의 합은 일반적으로 RSS 방식을 사용하여 구하게 됩니다.
(RSS = 제곱을 취하는 방법, Residual Sum of Square)
정리하자면, 머신러닝 기반 회귀의 핵심은
RSS를 최소로 하는 회귀계수를 학습을 통해 찾는 것 입니다 !
선형회귀에는 다양한 평가지표가 존재합니다.
실제값과 회귀예측값의 차이 값을 기반으로 한 지표가 중심이지만,
+와 -가 섞여 오류가 상쇄되기 때문에 절댓값, 제곱 등의 방법을 함께 활용합니다.
- MSE : 실제 값과 예측값의 차이를 제곱해 평균한 값
- R2 : 실제 값과 분산 대비 예측값의 분산 비율을 지표로 하여,
1에 가까울수록 예측 정확도 높음
코드 실습을 통해 회귀 분석에 대해 자세히 알아보겠습니다.
사이킷런의 LinearRegression 주택 가격 예측 실습

1. 사이킷런에서 제공하는 보스턴 주택 가격 데이터 세트 불러오기

▶ 기본 라이브러리인 numpy, matlotlib, pandas, seaborn을 불러오고,
사이킷런에서 제공하는 데이터 세트를 불러오기 위해 load_boston 을 임포트
▶ 데이터프레임 변환
▶ y값 즉, 종속변수인 주택 가격(PRICE) 컬럼을 bostonDF에 추가
▶ 데이터 프레임 확인

2. 선형 회귀 분석 진행

▶ 독립변수 & 종속변수 = x와 y 분리
▷ X_data에는 종속변수 PRICE 컬럼을 제외한 모든 변수 저장
▷ y_target에는 PRICE 컬럼만 저장
▶ train_test_split()으로 학습, 테스트 데이터 세트 분리하여 학습 및 예측 수행
▷ train : 최적의 모델을 학습시키기 위한 학습 데이터 세트
▷ test : 평가 시 사용할 테스트 데이터 세트
▷ test_size 파라미터 : 7:3으로 분리
▶ 예측 수행
▷ train 데이터에 fit 함수로 학습
▷ X_test를 학습시켜 y_preds로 예측값 저장
▷ 실제값 = y_test, 예측값 = y_preds
▶ metrics 모듈의 mean_squared_error(), r2_score() 사용해 MSE와 R2 Score 측정
▶ MSE, R2 Score 도출
▶ LinearRegression 모델의 intercept = 절편, coef = 회귀 계수

▶ 파악하기 쉽게 정렬 → RM이라는 컬럼이 가장 중요
오늘 배워본 방법 외에도
회귀분석을 실행할 다양한 방법들이 존재합니다.
대표적인 방법으로는 릿지, 라쏘, 로지스틱 회귀 분석 등이 있는데요.
이 뿐만 아니라 최적의 선형모델을 도출하기 위한
스케일링 및 정규화 방법들도 존재하니,
해당 포스팅 외에도 검색이나 교재 실습 등을 통해
다양한 인사이트를 얻어 회귀분석을 완벽히 이해하시길 바랍니다 !
저희 ball 역시 이후 포스팅들에서 회귀분석에 대해
꾸준히 언급할 예정이니 기대해주세요 🙂
다음에 더 유익한 내용으로 찾아오겠습니다 !
'데이터 분석 공부' 카테고리의 다른 글
| SQL 입문 , 데이터베이스에 대해 알아보자. (1) | 2023.10.01 |
|---|---|
| 맵박스(Mapbox)를 활용해 나만의 태블로 커스텀 맵 만드는 법 (0) | 2023.08.20 |
| 태블로 프렙(Tableau Prep), 간단히 마스터하기 (0) | 2023.06.20 |
| 사이킷런에 대해 소개합니다! (0) | 2023.05.20 |
| 태블로의 다양한 차트를 소개합니다! (0) | 2023.04.20 |